Peace Tech
What is Peace Speech?.
As part of this effort to uncover peace speech, the Sustaining Peace Project has worked with cohorts of data scientist master’s students through the Data Science Institute (DSI) at Columbia University for the past 3 years. This fall marks the third DSI cohort, where we ran data from two major source categories: news media and Twitter. News sources were found through web scraping techniques (i.e. sources whose data were accessible to the public online for processing) and the Twitter posts collected included only sources where the location of the post could be verified (via GPS tracking).
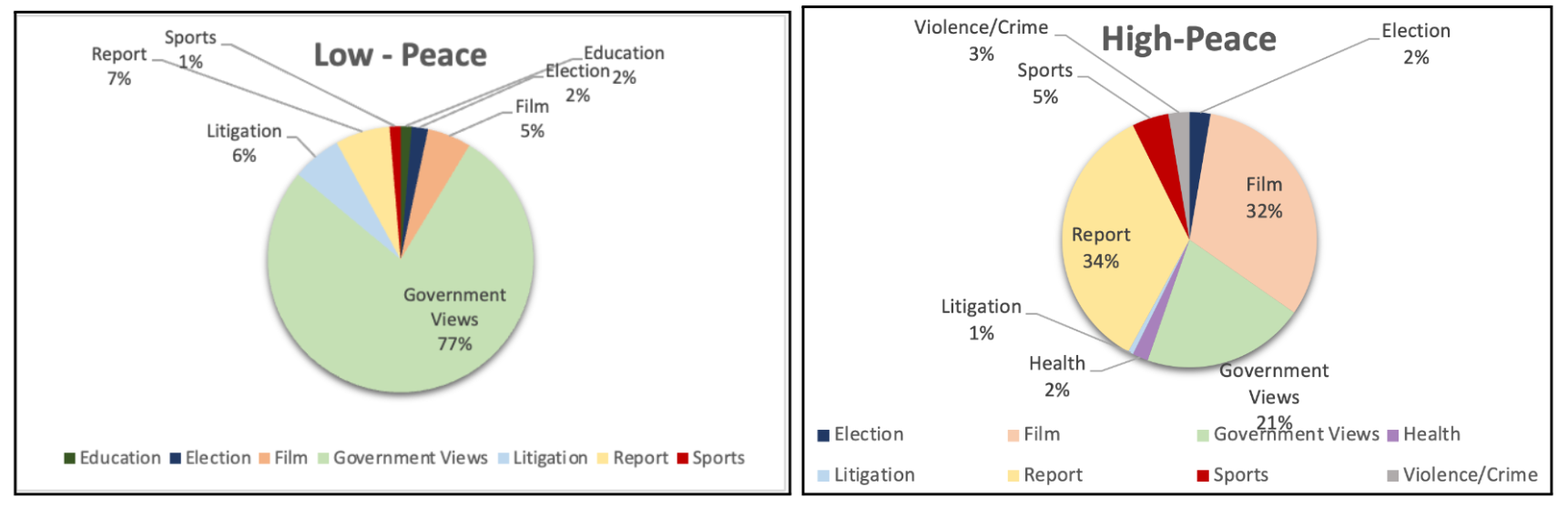
Findings: Although there seemed little different between high-peace and low-peace countries in the Twitter data, the news media sources showed a similar pattern as with past data collection: language from high-peace countries seemed to cover a wider range of topics, with words referring to art, sports, daily activities, and seasons, whereas language from low-peace countries were more narrow in scope, with words referring to social order and control, governance, law and policy.
A New Consideration: Typically, the Peace Speech project has been committed to generating meaningful lists of peaceful and non-peaceful words - letting the data tell us what it finds instead of looking for words we believe should be peaceful or not. Something the data reveals to us is there are words that, in context, may relate to peacefulness, but we understand the words may not in and of themselves always indicate peacefulness. For instance, words like “time” or “ball” could be used in a whole variety of ways! So if individual words may not indicate peacefulness, how can we understand differences in the language? This DSI cohort tackled this problem by using a method called “clustering.” Through telling the machine learning algorithm to build clusters with words that are similar to one another, the DSI students were able to find some significant categories of words. Now only did these clusters contribute to the findings above, they left us with new considerations for how we can move the study forward and draw more meaning of types of words / use of language in peaceful versus non-peaceful societies.
Below is a link to a pie chart one of our DSI students created to show the percentage of word cluster topics present in high-peace versus low-peace countries.
What’s Next:
- Further explore the potential of word clusters – can they help us find new linguistic differences between high- and low-peace countries? Can clusters help us to more effectively and efficiently eliminate data bias?
- Apply techniques of natural language processing used in this recent DSI cohort to larger and new datasets (including through news sources and social media)
- Build a peace speech index!
You can read more on the background of the peace speech project here! peace speech

{kind=link}